機械語利用
インタプリタは、ユーザーがワードを定義すると アセンブラを使い機械語へと変換後、辞書と呼ぶ 領域に格納します。 ワードを定義したときには、辞書の中に機械語に翻訳した プログラムコードが格納されるので、ワード利用が機械語 利用と等価で、高速処理が約束されます。 ユーザーが、機械語をそのままワードとして与えるカラクリが 用意されています。 ワード「[char ] *」を利用すれば、機械語をそのまま メモリに入れることができます。 実際のワード定義では、どう利用するのかをtarボールの 中に入っていたサンプルコードから抜粋してみます。 : sqrt ( u -- u^1/2 ) [ $2040 h, ¥ movs r0, #0x40 $0600 h, ¥ lsls r0, #24 $2100 h, ¥ movs r1, #0 $000A h, ¥ 1:movs r2, r1 $4302 h, ¥ orrs r2, r0 $0849 h, ¥ lsrs r1, #1 $4296 h, ¥ cmp r6, r2 $D301 h, ¥ blo 2f $1AB6 h, ¥ subs r6, r2 $4301 h, ¥ orrs r1, r0 $0880 h, ¥ 2:lsrs r0, #2 $D1F6 h, ¥ bne 1b $000E h, ¥ movs r6, r1 ] 1-foldable ; ワード「[ ]」は、バイトごとにメモリにデータを格納できます。 Forthを利用しているため、「スタックに数値を入れてから ワードを使ってスタックを操作する。」という操作に即した 記述になるように工夫されています。 データをスタックではなく、指定エリアに保存するため 数値に続けてポインタ処理のワードをおきます。 $2040 h, ¥ movs r0, #0x40 は、数値をスタックに入れ ワード h で、スタックに入っている数値を、メモリに転送 すると解釈されます。 本来ワード「[ ]」では、バイト単位の転送になりますが 32ビットを1ワードとするARMでは、32ビット、16ビット の転送には専用ワードで対応する必要があります。 $2040 h は、スタックにある数値を、16ビットとみなし 上位バイト、下位バイトの順番にメモリへと転送する 指定になります。 ワード「h」は、half wordを扱うことを意味します。 4バイト=32ビットのためには、ワード「cells」、「cells+」 を利用できるようになっています。 「cells」は、32ビットのデータそのものを表現し 「cells+」は、バイトでアドレスをふっているので 4バイトのアドレスを、一気にインクリメント することができます。 32ビット、16ビットの値をメモリに格納するには ビックエンディアン、リトルエンディアンの選択 をして、各バイトの並び方を指定します。 ワード「[ ]」の内部で、ワード「h」を利用すると、ビック エンディアンでの保存を指定したことになります。 図でみると、以下。メモリには、アドレスが割り当てられていて、アドレスの 小さい方にレジスタや数値の上側の値を格納していきます。 このようなデータ格納方式を、ビッグエンディアンと呼びます。 リトルエンディアンは、レジスタや値の小さいビット位置の値 を、アドレスの小さい方へ格納していきます。 機械語は、複数の命令を組み合わせて、実現したい内容を 表現するので、ワード「,」を使って、上から下に16ビット を保存する処理を並べていきます。 Forthインタプリタには、デファクトスタンダードのワードの 管理テーブルがあり、4つの領域を利用します。 管理テーブルの仕様は、以下。
4つのアドレスフィールドが用意され、次の名称がついてます。
- NFA(Name Field Address)
- LFA(Link Field Address)
- CFA(Code Field Address)
- PFA(Parameter Field Address)
- ワード名称のバイト数(最大32文字)
- Forth仕様のワードを示すフラグ
- 機械語仕様のワードを示すフラグ
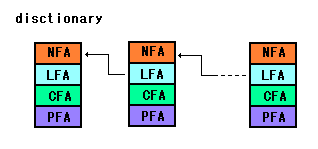 常に、そのワードの前に定義されているワードのNFAの
エントリーアドレスを格納しています。
辞書の最後から、最初に向けてLFAをたどっていくと
定義されているワードを探し出すことができます。
CFA(Code Field Address)
定義したワードが、数値を表現していないときは
実行シーケンスを格納したエリアの先頭アドレス
を格納しています。
常に、そのワードの前に定義されているワードのNFAの
エントリーアドレスを格納しています。
辞書の最後から、最初に向けてLFAをたどっていくと
定義されているワードを探し出すことができます。
CFA(Code Field Address)
定義したワードが、数値を表現していないときは
実行シーケンスを格納したエリアの先頭アドレス
を格納しています。
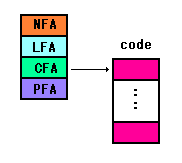 実行シーケンスは、どこにあってもよいので
ROM、RAMに無関係に実行シーケンスを入れて
おけます。
ワードを再定義しても、CFAの内容を変更するだけで済みます。
機械語を利用する場合、ARMには、32ビット命令の他に
16ビット命令があります。
16ビット命令は、THUMB、THUMB2の2種の命令があります。
レジスタとレジスタ、レジスタとメモリの間のやり取りに
限定したアセンブラを作って対応します。
AWKで作ったARMのアセンブラは、以下。
#
function get_reg_code(x) {
# default
result = "111"
# search
if ( x == "R0" ) { result = "000" ; }
if ( x == "R1" ) { result = "001" ; }
if ( x == "R2" ) { result = "010" ; }
if ( x == "R3" ) { result = "011" ; }
return result
}
#
function get_num_bin3(x) {
# default
r2 = "0"
r1 = "0"
r0 = "0"
# calculate
if ( x >= 4 ) {
r2 = "1"
x = x - 4
}
if ( x >= 2 ) {
r1 = "1"
x = x - 2
}
if ( x > 0 ) { r0 = "1" }
# concatenate
result = r2 r1 r0
return result
}
#
function get_num_bin5(x) {
# default
r4 = "0"
r3 = "0"
# calculate
if ( x >= 16 ) {
r4 = "1"
x = x - 16
}
if ( x >= 8 ) {
r3 = "1"
x = x - 8
}
# copy
y = x
# concatenate
result = r4 r3 get_num_bin3(y)
return result
}
#
function get_num_bin8(x) {
# default
r7 = "0"
r6 = "0"
r5 = "0"
# calculate
if ( x >= 128 ) {
r7 = "1"
x = x - 128
}
if ( x >= 64 ) {
r6 = "1"
x = x - 64
}
if ( x >= 32 ) {
r5 = "1"
x = x - 32
}
# copy
y = x
# concatenate
result = r7 r6 r5 get_num_bin5(y)
return result
}
#
function get_num_bin11(x) {
# default
r10 = "0"
r9 = "0"
r8 = "0"
# calculate
if ( x >= 1024 ) {
r10 = "1"
x = x - 1024
}
if ( x >= 512 ) {
r9 = "1"
x = x - 512
}
if ( x >= 256 ) {
r8 = "1"
x = x - 256
}
# copy
y = x
# concatenate
result = r10 r9 r8 get_num_bin8(y)
return result
}
# main
{
# get field size
len = NF
#
printf("%s => ",$0)
#
if ( len == 1 ) {
# RET // 0100_0111_0111_0000
if ( toupper($1) == "RET" ) {
printf("0100011101110000¥n")
}
}
if ( len == 2 ) {
# GOTO n11 // 11100 n11<00000000000>
if ( toupper($1) == "GOTO" ) {
tt = $2
if ( $2 < 0 ) { tt = 254 + $2 }
uu = get_num_bin11(tt)
xcode = "11100"
}
printf("%s%s¥n",xcode,uu)
}
if ( len == 3 ) {
# substitute
# Rd = u8 // 00100 Rd<000> u8<00000000>
# Rd = Rm // 0100011000 Rm <000> Rd<000>
if ( $2 == "=" ) {
dd = get_reg_code(toupper($1))
if ( 0 <= $3 && $3 <= 255 ) {
ss = get_num_bin8($3)
xcode = "00100"
} else {
ss = get_reg_code(toupper($3))
xcode = "0100011000"
}
printf("%s%s%s¥n",xcode,dd,ss)
}
# add or subtract
# Rd += u8 // 00110 Rd<000> u8<00000000>
# Rd -= u8 // 00111 Rd<000> u8<00000000>
if ( $2 == "+=" || $2 == "-=" ) {
dd = get_reg_code(toupper($1))
ss = get_num_bin8($3)
xcode = "00110"
if ( $2 == "-=" ) { xcode = "00111" }
printf("%s%s%s¥n",xcode,dd,ss)
}
# logical AND , exclusive OR , OR
# Rd &= Rm // 0100000000 Rm<000> Rd<000>
# Rd ^= Rm // 0100000001 Rm<000> Rd<000>
# Rd |= Rm // 0100001100 Rm<000> Rd<000>
if ( $2 == "&=" || $2 == "^=" || $2 == "|=" ) {
dd = get_reg_code(toupper($1))
ss = get_reg_code(toupper($3))
xcode = "0100000000"
if ( $2 == "^=" ) { xcode = "0100000001" }
if ( $2 == "|=" ) { xcode = "0100001100" }
printf("%s%s%s¥n",xcode,ss,dd)
}
# multiply , left shift , right shift
# Rd *= Rm // 0100001101 Rm<000> Rd<000>
# Rd <<= Rs // 0100000010 Rs<000> Rd<000>
# Rd >>= Rs // 0100000011 Rs<000> Rd<000>
if ( $2 == "*=" || $2 == "<<=" || $2 == ">>=" ) {
dd = get_reg_code(toupper($1))
ss = get_reg_code(toupper($3))
xcode = "0100001101"
if ( $2 == "<<=" ) { xcode = "0100000010" }
if ( $2 == ">>=" ) { xcode = "0100000011" }
printf("%s%s%s¥n",xcode,ss,dd)
}
# condition Rn - u8 // 00101 Rn<000> u8<00000000>
# condition Rn - Rm // 0100001010 Rm<000> Rn<000>
if ( $2 == "-" ) {
dd = get_reg_code(toupper($1))
if ( 0 <= $3 && $3 <= 255 ) {
ss = get_num_bin8($3)
xcode = "00101"
} else {
ss = get_reg_code(toupper($3))
xcode = "0100001010"
}
printf("%s%s%s¥n",xcode,dd,ss)
}
# condition Rn & Rm // 0100001000 Rm<000> Rn<000>
if ( $2 == "&" ) {
dd = get_reg_code(toupper($1))
ss = get_reg_code(toupper($3))
xcode = "0100001000"
printf("%s%s%s¥n",xcode,ss,dd)
}
# Rd = -Rm // 0100001001 Rm<000> Rd<000>
if ( $3 == "-R0" || $3 == "-R1" || $3 == "-R2" || $3 == "-R3" ) {
dd = get_reg_code(toupper($1))
# select
ss = get_reg_code("R0")
if ( $3 == "-R1" ) { ss = get_reg_code("R1") }
if ( $3 == "-R2" ) { ss = get_reg_code("R2") }
if ( $3 == "-R3" ) { ss = get_reg_code("R3") }
#
xcode = "0100001001"
printf("%s%s%s¥n",xcode,ss,dd)
}
# Rd &= ‾Rm // 0100001110 Rm<000> Rd<000>
# Rd = ‾Rm // 0100001111 Rm<000> Rd<000>
if ( $3 == "‾R0" || $3 == "‾R1" || $3 == "‾R2" || $3 == "‾R3" ) {
dd = get_reg_code(toupper($1))
# select
ss = get_reg_code("R0")
if ( $3 == "‾R1" ) { ss = get_reg_code("R1") }
if ( $3 == "‾R2" ) { ss = get_reg_code("R2") }
if ( $3 == "‾R3" ) { ss = get_reg_code("R3") }
#
if ( $2 == "&=" ) { xcode = "0100001110" }
if ( $2 == "=" ) { xcode = "0100001111" }
printf("%s%s%s¥n",xcode,ss,dd)
}
}
if ( len == 4 ) {
# IF 0 GOTO n8 // 11010000 n8<00000000>
# IF !0 GOTO n8 // 11010001 n8<00000000>
if ( $1 == "IF" ) {
tt = $4
if ( $4 < 0 ) { tt = 254 + $4 }
uu = get_num_bin8(tt)
# select
xcode = "11010000"
if ( $2 == "!0" ) { xcode = "11010001" }
printf("%s%s¥n",xcode,uu)
}
}
if ( len == 5 ) {
if ( $2 == "=" ) {
# shift
# Rd = Rm << u5 // 00000 u5<00000> Rm<000> Rd<000>
# Rd = Rm >> u5 // 00001 u5<00000> Rm<000> Rd<000>
if ( $4 == "<<" || $4 == ">>" ) {
dd = get_reg_code(toupper($1))
ss = get_reg_code(toupper($3))
uu = get_num_bin5($5)
if ( $4 == "<<" ) { xcode = "00000" }
if ( $4 == ">>" ) { xcode = "00001" }
printf("%s%s%s%s¥n",xcode,uu,ss,dd)
}
# add
# Rd = Rn + Rm // 0001100 Rm<000> Rn<000> Rd<000>
# Rd = Rn + u3 // 0001110 u3<000> Rm<000> Rd<000>
if ( $4 == "+" ) {
dd = get_reg_code(toupper($1))
ss = get_reg_code(toupper($3))
if ( 0 <= $5 && $5 <= 7 ) {
uu = get_num_bin3($5)
xcode = "0001110"
} else {
uu = get_reg_code(toupper($5))
xcode = "0001100"
}
printf("%s%s%s%s¥n",xcode,uu,ss,dd)
}
# subtract
# Rd = Rn - Rm // 0001100 Rm<000> Rn<000> Rd<000>
# Rd = Rn - u3 // 0001111 u3<000> Rm<000> Rd<000>
if ( $4 == "-" ) {
dd = get_reg_code(toupper($1))
ss = get_reg_code(toupper($3))
if ( 0 <= $5 && $5 <= 7 ) {
uu = get_num_bin3($5)
xcode = "0001111"
} else {
uu = get_reg_code(toupper($5))
xcode = "0001100"
}
printf("%s%s%s%s¥n",xcode,uu,ss,dd)
}
}
}
if ( len == 7 ) {
# Rd = [ Rn + u5 ] // 01111 u5<00000> Rn<000> Rd<000>
# Rd = [ Rn + Rm ] // 0101110 Rm<000> Rn<000> Rd<000>
if ( $2 == "=" && $3 == "[" && $5 = "+" && $7 == "]" ) {
dd = get_reg_code(toupper($1))
ss = get_reg_code(toupper($4))
if ( 0 <= $6 && $6 <= 31 ) {
uu = get_num_bin5($6)
xcode = "01111"
} else {
uu = get_reg_code(toupper($6))
xcode = "0101110"
}
printf("%s%s%s%s¥n",xcode,uu,ss,dd)
}
# [ Rn + u5 ] = Rd // 01110 u5<00000> Rn<000> Rd<000>
# [ Rn + Rm ] = Rd // 0101010 Rm<000> Rn<000> Rd<000>
if ( $1 == "[" && $3 == "+" && $5 = "]" && $6 == "=" ) {
dd = get_reg_code(toupper($7))
ss = get_reg_code(toupper($2))
if ( 0 <= $4 && $4 <= 31 ) {
uu = get_num_bin5($4)
xcode = "01110"
} else {
uu = get_reg_code(toupper($4))
xcode = "0101010"
}
printf("%s%s%s%s¥n",xcode,uu,ss,dd)
}
}
# access with long or word size
if ( len == 8 ) {
# Rd = [ Rn + u5 ] W // 10001 u5/2 <00000> Rn<000> Rd<000>
# Rd = [ Rn + u5 ] L // 01101 u5/4 <00000> Rn<000> Rd<000>
# Rd = [ Rn + Rm ] W // 0101101 Rm<000> Rn<000> Rd<000>
# Rd = [ Rn + Rm ] L // 0101100 Rm<000> Rn<000> Rd<000>
if ( $2 == "=" && $3 == "[" && $5 = "+" && $7 == "]" ) {
dd = get_reg_code(toupper($1))
ss = get_reg_code(toupper($4))
if ( 0 <= $6 && $6 <= 31 ) {
if ( $8 == "W" ) {
uu = get_num_bin5($6/2)
xcode = "10001"
}
if ( $8 == "L" ) {
uu = get_num_bin5($6/4)
xcode = "01101"
}
} else {
uu = get_reg_code(toupper($6))
if ( $8 == "W" ) { xcode = "0101101" }
if ( $8 == "L" ) { xcode = "0101100" }
}
printf("%s%s%s%s¥n",xcode,uu,ss,dd)
}
# [ Rn + u5 ] W = Rd // 10000 u5/2 <00000> Rn<000> Rd<000>
# [ Rn + u5 ] L = Rd // 01100 u5/4 <00000> Rn<000> Rd<000>
# [ Rn + Rm ] W = Rd // 0101001 Rm<000> Rn<000> Rd<000>
# [ Rn + Rm ] L = Rd // 0101000 Rm<000> Rn<000> Rd<000>
if ( $1 == "[" && $3 == "+" && $5 = "]" && $7 == "=" ) {
dd = get_reg_code(toupper($2))
ss = get_reg_code(toupper($8))
if ( 0 <= $4 && $4 <= 31 ) {
if ( $6 == "W" ) {
uu = get_num_bin5($4/2)
xcode = "10000"
}
if ( $6 == "L" ) {
uu = get_num_bin5($4/4)
xcode = "01100"
}
} else {
uu = get_reg_code(toupper($4))
if ( $8 == "W" ) { xcode = "0101001" }
if ( $8 == "L" ) { xcode = "0101000" }
}
printf("%s%s%s%s¥n",xcode,uu,ss,dd)
}
}
# PUSH or POP
if ( $1 == "PUSH" || $1 == "POP" ) {
sum = 0
# search
for ( i = 3 ; i < NF+1 ; i++ ) {
if ( $i == "R0" ) { sum = sum + 1 }
if ( $i == "R1" ) { sum = sum + 2 }
if ( $i == "R2" ) { sum = sum + 4 }
if ( $i == "R3" ) { sum = sum + 8 }
if ( $i == "R4" ) { sum = sum + 16 }
if ( $i == "R5" ) { sum = sum + 32 }
if ( $i == "R6" ) { sum = sum + 64 }
if ( $i == "R7" ) { sum = sum + 128 }
}
# convert
uu = get_num_bin8( sum )
if ( $1 == "PUSH" ) { xcode = "10110100" }
if ( $1 == "POP" ) { xcode = "10111100" }
#
printf("%s%s¥n",xcode,uu)
}
}
利用するときは、次のようにタイプ(プロンプトは省略)。
gawk -f asm15x.awk tt1.asm > tt1.txt{enter}
I/Oリダイレクトで、ファイルに出力したので
その内容をみてみます。(見易くしてます。)
R3 = 9 => 0010001100001001
R3 = R3 << 8 => 0000001000011011
[ R1 + R3 ] = R3 => 0101010011001011
R3 = R3 + 1 => 0001110001011011
R2 = R3 >> 8 => 0000101000011010
R2 - 10 => 0010101000001010
IF !0 GOTO -4 => 1101000111111010
RET => 0100011101110000
PFA(Parameter Field Address)
ワードが数値を必要とする場合、このフィールドに
格納するか、パラメータの格納しているエリアの先頭
アドレスを格納します。
実行シーケンスは、どこにあってもよいので
ROM、RAMに無関係に実行シーケンスを入れて
おけます。
ワードを再定義しても、CFAの内容を変更するだけで済みます。
機械語を利用する場合、ARMには、32ビット命令の他に
16ビット命令があります。
16ビット命令は、THUMB、THUMB2の2種の命令があります。
レジスタとレジスタ、レジスタとメモリの間のやり取りに
限定したアセンブラを作って対応します。
AWKで作ったARMのアセンブラは、以下。
#
function get_reg_code(x) {
# default
result = "111"
# search
if ( x == "R0" ) { result = "000" ; }
if ( x == "R1" ) { result = "001" ; }
if ( x == "R2" ) { result = "010" ; }
if ( x == "R3" ) { result = "011" ; }
return result
}
#
function get_num_bin3(x) {
# default
r2 = "0"
r1 = "0"
r0 = "0"
# calculate
if ( x >= 4 ) {
r2 = "1"
x = x - 4
}
if ( x >= 2 ) {
r1 = "1"
x = x - 2
}
if ( x > 0 ) { r0 = "1" }
# concatenate
result = r2 r1 r0
return result
}
#
function get_num_bin5(x) {
# default
r4 = "0"
r3 = "0"
# calculate
if ( x >= 16 ) {
r4 = "1"
x = x - 16
}
if ( x >= 8 ) {
r3 = "1"
x = x - 8
}
# copy
y = x
# concatenate
result = r4 r3 get_num_bin3(y)
return result
}
#
function get_num_bin8(x) {
# default
r7 = "0"
r6 = "0"
r5 = "0"
# calculate
if ( x >= 128 ) {
r7 = "1"
x = x - 128
}
if ( x >= 64 ) {
r6 = "1"
x = x - 64
}
if ( x >= 32 ) {
r5 = "1"
x = x - 32
}
# copy
y = x
# concatenate
result = r7 r6 r5 get_num_bin5(y)
return result
}
#
function get_num_bin11(x) {
# default
r10 = "0"
r9 = "0"
r8 = "0"
# calculate
if ( x >= 1024 ) {
r10 = "1"
x = x - 1024
}
if ( x >= 512 ) {
r9 = "1"
x = x - 512
}
if ( x >= 256 ) {
r8 = "1"
x = x - 256
}
# copy
y = x
# concatenate
result = r10 r9 r8 get_num_bin8(y)
return result
}
# main
{
# get field size
len = NF
#
printf("%s => ",$0)
#
if ( len == 1 ) {
# RET // 0100_0111_0111_0000
if ( toupper($1) == "RET" ) {
printf("0100011101110000¥n")
}
}
if ( len == 2 ) {
# GOTO n11 // 11100 n11<00000000000>
if ( toupper($1) == "GOTO" ) {
tt = $2
if ( $2 < 0 ) { tt = 254 + $2 }
uu = get_num_bin11(tt)
xcode = "11100"
}
printf("%s%s¥n",xcode,uu)
}
if ( len == 3 ) {
# substitute
# Rd = u8 // 00100 Rd<000> u8<00000000>
# Rd = Rm // 0100011000 Rm <000> Rd<000>
if ( $2 == "=" ) {
dd = get_reg_code(toupper($1))
if ( 0 <= $3 && $3 <= 255 ) {
ss = get_num_bin8($3)
xcode = "00100"
} else {
ss = get_reg_code(toupper($3))
xcode = "0100011000"
}
printf("%s%s%s¥n",xcode,dd,ss)
}
# add or subtract
# Rd += u8 // 00110 Rd<000> u8<00000000>
# Rd -= u8 // 00111 Rd<000> u8<00000000>
if ( $2 == "+=" || $2 == "-=" ) {
dd = get_reg_code(toupper($1))
ss = get_num_bin8($3)
xcode = "00110"
if ( $2 == "-=" ) { xcode = "00111" }
printf("%s%s%s¥n",xcode,dd,ss)
}
# logical AND , exclusive OR , OR
# Rd &= Rm // 0100000000 Rm<000> Rd<000>
# Rd ^= Rm // 0100000001 Rm<000> Rd<000>
# Rd |= Rm // 0100001100 Rm<000> Rd<000>
if ( $2 == "&=" || $2 == "^=" || $2 == "|=" ) {
dd = get_reg_code(toupper($1))
ss = get_reg_code(toupper($3))
xcode = "0100000000"
if ( $2 == "^=" ) { xcode = "0100000001" }
if ( $2 == "|=" ) { xcode = "0100001100" }
printf("%s%s%s¥n",xcode,ss,dd)
}
# multiply , left shift , right shift
# Rd *= Rm // 0100001101 Rm<000> Rd<000>
# Rd <<= Rs // 0100000010 Rs<000> Rd<000>
# Rd >>= Rs // 0100000011 Rs<000> Rd<000>
if ( $2 == "*=" || $2 == "<<=" || $2 == ">>=" ) {
dd = get_reg_code(toupper($1))
ss = get_reg_code(toupper($3))
xcode = "0100001101"
if ( $2 == "<<=" ) { xcode = "0100000010" }
if ( $2 == ">>=" ) { xcode = "0100000011" }
printf("%s%s%s¥n",xcode,ss,dd)
}
# condition Rn - u8 // 00101 Rn<000> u8<00000000>
# condition Rn - Rm // 0100001010 Rm<000> Rn<000>
if ( $2 == "-" ) {
dd = get_reg_code(toupper($1))
if ( 0 <= $3 && $3 <= 255 ) {
ss = get_num_bin8($3)
xcode = "00101"
} else {
ss = get_reg_code(toupper($3))
xcode = "0100001010"
}
printf("%s%s%s¥n",xcode,dd,ss)
}
# condition Rn & Rm // 0100001000 Rm<000> Rn<000>
if ( $2 == "&" ) {
dd = get_reg_code(toupper($1))
ss = get_reg_code(toupper($3))
xcode = "0100001000"
printf("%s%s%s¥n",xcode,ss,dd)
}
# Rd = -Rm // 0100001001 Rm<000> Rd<000>
if ( $3 == "-R0" || $3 == "-R1" || $3 == "-R2" || $3 == "-R3" ) {
dd = get_reg_code(toupper($1))
# select
ss = get_reg_code("R0")
if ( $3 == "-R1" ) { ss = get_reg_code("R1") }
if ( $3 == "-R2" ) { ss = get_reg_code("R2") }
if ( $3 == "-R3" ) { ss = get_reg_code("R3") }
#
xcode = "0100001001"
printf("%s%s%s¥n",xcode,ss,dd)
}
# Rd &= ‾Rm // 0100001110 Rm<000> Rd<000>
# Rd = ‾Rm // 0100001111 Rm<000> Rd<000>
if ( $3 == "‾R0" || $3 == "‾R1" || $3 == "‾R2" || $3 == "‾R3" ) {
dd = get_reg_code(toupper($1))
# select
ss = get_reg_code("R0")
if ( $3 == "‾R1" ) { ss = get_reg_code("R1") }
if ( $3 == "‾R2" ) { ss = get_reg_code("R2") }
if ( $3 == "‾R3" ) { ss = get_reg_code("R3") }
#
if ( $2 == "&=" ) { xcode = "0100001110" }
if ( $2 == "=" ) { xcode = "0100001111" }
printf("%s%s%s¥n",xcode,ss,dd)
}
}
if ( len == 4 ) {
# IF 0 GOTO n8 // 11010000 n8<00000000>
# IF !0 GOTO n8 // 11010001 n8<00000000>
if ( $1 == "IF" ) {
tt = $4
if ( $4 < 0 ) { tt = 254 + $4 }
uu = get_num_bin8(tt)
# select
xcode = "11010000"
if ( $2 == "!0" ) { xcode = "11010001" }
printf("%s%s¥n",xcode,uu)
}
}
if ( len == 5 ) {
if ( $2 == "=" ) {
# shift
# Rd = Rm << u5 // 00000 u5<00000> Rm<000> Rd<000>
# Rd = Rm >> u5 // 00001 u5<00000> Rm<000> Rd<000>
if ( $4 == "<<" || $4 == ">>" ) {
dd = get_reg_code(toupper($1))
ss = get_reg_code(toupper($3))
uu = get_num_bin5($5)
if ( $4 == "<<" ) { xcode = "00000" }
if ( $4 == ">>" ) { xcode = "00001" }
printf("%s%s%s%s¥n",xcode,uu,ss,dd)
}
# add
# Rd = Rn + Rm // 0001100 Rm<000> Rn<000> Rd<000>
# Rd = Rn + u3 // 0001110 u3<000> Rm<000> Rd<000>
if ( $4 == "+" ) {
dd = get_reg_code(toupper($1))
ss = get_reg_code(toupper($3))
if ( 0 <= $5 && $5 <= 7 ) {
uu = get_num_bin3($5)
xcode = "0001110"
} else {
uu = get_reg_code(toupper($5))
xcode = "0001100"
}
printf("%s%s%s%s¥n",xcode,uu,ss,dd)
}
# subtract
# Rd = Rn - Rm // 0001100 Rm<000> Rn<000> Rd<000>
# Rd = Rn - u3 // 0001111 u3<000> Rm<000> Rd<000>
if ( $4 == "-" ) {
dd = get_reg_code(toupper($1))
ss = get_reg_code(toupper($3))
if ( 0 <= $5 && $5 <= 7 ) {
uu = get_num_bin3($5)
xcode = "0001111"
} else {
uu = get_reg_code(toupper($5))
xcode = "0001100"
}
printf("%s%s%s%s¥n",xcode,uu,ss,dd)
}
}
}
if ( len == 7 ) {
# Rd = [ Rn + u5 ] // 01111 u5<00000> Rn<000> Rd<000>
# Rd = [ Rn + Rm ] // 0101110 Rm<000> Rn<000> Rd<000>
if ( $2 == "=" && $3 == "[" && $5 = "+" && $7 == "]" ) {
dd = get_reg_code(toupper($1))
ss = get_reg_code(toupper($4))
if ( 0 <= $6 && $6 <= 31 ) {
uu = get_num_bin5($6)
xcode = "01111"
} else {
uu = get_reg_code(toupper($6))
xcode = "0101110"
}
printf("%s%s%s%s¥n",xcode,uu,ss,dd)
}
# [ Rn + u5 ] = Rd // 01110 u5<00000> Rn<000> Rd<000>
# [ Rn + Rm ] = Rd // 0101010 Rm<000> Rn<000> Rd<000>
if ( $1 == "[" && $3 == "+" && $5 = "]" && $6 == "=" ) {
dd = get_reg_code(toupper($7))
ss = get_reg_code(toupper($2))
if ( 0 <= $4 && $4 <= 31 ) {
uu = get_num_bin5($4)
xcode = "01110"
} else {
uu = get_reg_code(toupper($4))
xcode = "0101010"
}
printf("%s%s%s%s¥n",xcode,uu,ss,dd)
}
}
# access with long or word size
if ( len == 8 ) {
# Rd = [ Rn + u5 ] W // 10001 u5/2 <00000> Rn<000> Rd<000>
# Rd = [ Rn + u5 ] L // 01101 u5/4 <00000> Rn<000> Rd<000>
# Rd = [ Rn + Rm ] W // 0101101 Rm<000> Rn<000> Rd<000>
# Rd = [ Rn + Rm ] L // 0101100 Rm<000> Rn<000> Rd<000>
if ( $2 == "=" && $3 == "[" && $5 = "+" && $7 == "]" ) {
dd = get_reg_code(toupper($1))
ss = get_reg_code(toupper($4))
if ( 0 <= $6 && $6 <= 31 ) {
if ( $8 == "W" ) {
uu = get_num_bin5($6/2)
xcode = "10001"
}
if ( $8 == "L" ) {
uu = get_num_bin5($6/4)
xcode = "01101"
}
} else {
uu = get_reg_code(toupper($6))
if ( $8 == "W" ) { xcode = "0101101" }
if ( $8 == "L" ) { xcode = "0101100" }
}
printf("%s%s%s%s¥n",xcode,uu,ss,dd)
}
# [ Rn + u5 ] W = Rd // 10000 u5/2 <00000> Rn<000> Rd<000>
# [ Rn + u5 ] L = Rd // 01100 u5/4 <00000> Rn<000> Rd<000>
# [ Rn + Rm ] W = Rd // 0101001 Rm<000> Rn<000> Rd<000>
# [ Rn + Rm ] L = Rd // 0101000 Rm<000> Rn<000> Rd<000>
if ( $1 == "[" && $3 == "+" && $5 = "]" && $7 == "=" ) {
dd = get_reg_code(toupper($2))
ss = get_reg_code(toupper($8))
if ( 0 <= $4 && $4 <= 31 ) {
if ( $6 == "W" ) {
uu = get_num_bin5($4/2)
xcode = "10000"
}
if ( $6 == "L" ) {
uu = get_num_bin5($4/4)
xcode = "01100"
}
} else {
uu = get_reg_code(toupper($4))
if ( $8 == "W" ) { xcode = "0101001" }
if ( $8 == "L" ) { xcode = "0101000" }
}
printf("%s%s%s%s¥n",xcode,uu,ss,dd)
}
}
# PUSH or POP
if ( $1 == "PUSH" || $1 == "POP" ) {
sum = 0
# search
for ( i = 3 ; i < NF+1 ; i++ ) {
if ( $i == "R0" ) { sum = sum + 1 }
if ( $i == "R1" ) { sum = sum + 2 }
if ( $i == "R2" ) { sum = sum + 4 }
if ( $i == "R3" ) { sum = sum + 8 }
if ( $i == "R4" ) { sum = sum + 16 }
if ( $i == "R5" ) { sum = sum + 32 }
if ( $i == "R6" ) { sum = sum + 64 }
if ( $i == "R7" ) { sum = sum + 128 }
}
# convert
uu = get_num_bin8( sum )
if ( $1 == "PUSH" ) { xcode = "10110100" }
if ( $1 == "POP" ) { xcode = "10111100" }
#
printf("%s%s¥n",xcode,uu)
}
}
利用するときは、次のようにタイプ(プロンプトは省略)。
gawk -f asm15x.awk tt1.asm > tt1.txt{enter}
I/Oリダイレクトで、ファイルに出力したので
その内容をみてみます。(見易くしてます。)
R3 = 9 => 0010001100001001
R3 = R3 << 8 => 0000001000011011
[ R1 + R3 ] = R3 => 0101010011001011
R3 = R3 + 1 => 0001110001011011
R2 = R3 >> 8 => 0000101000011010
R2 - 10 => 0010101000001010
IF !0 GOTO -4 => 1101000111111010
RET => 0100011101110000
PFA(Parameter Field Address)
ワードが数値を必要とする場合、このフィールドに
格納するか、パラメータの格納しているエリアの先頭
アドレスを格納します。
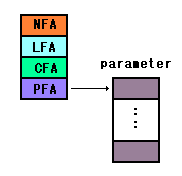 NFAのエントリーアドレスにある1バイトの中に、ワードが
数値の別名か実行シーケンスの名称かを格納しているので
数値か否かを判断できます。
Forthでは、変数もスタックに入れて使いますが
ワード「variable」を利用し、わかりやすくしたい
こともあるので、臨機応変に考えるべきでしょう。
4つのアドレスフィールドを使うと、辞書で使う場合の
テーブルの最小サイズは、33+4+4+4=45バイト。
実際に、どんな具合になっているのかは、ワード「words」で
表示させてみるとわかります。
NFAのエントリーアドレスにある1バイトの中に、ワードが
数値の別名か実行シーケンスの名称かを格納しているので
数値か否かを判断できます。
Forthでは、変数もスタックに入れて使いますが
ワード「variable」を利用し、わかりやすくしたい
こともあるので、臨機応変に考えるべきでしょう。
4つのアドレスフィールドを使うと、辞書で使う場合の
テーブルの最小サイズは、33+4+4+4=45バイト。
実際に、どんな具合になっているのかは、ワード「words」で
表示させてみるとわかります。
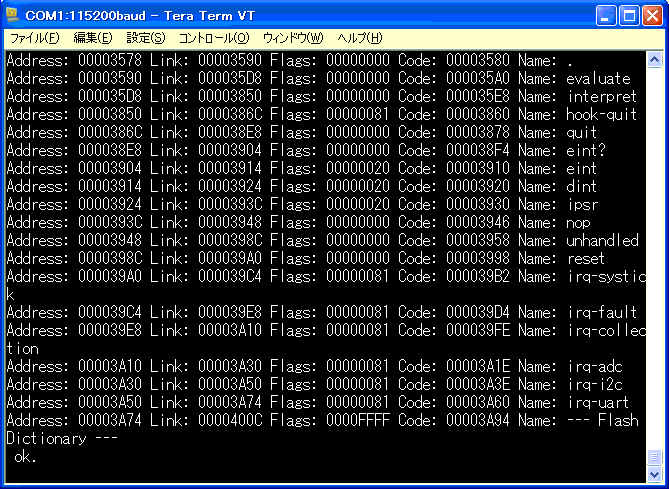 ワード「irq-uart」、「irq-i2c」、「irq-adc」は、辞書の
中でも隣り合っているとわかります。
アドレスが、$0003A50、$00003A30、$00003A10となって
いるため、32バイトごとなので、アドレスフィールドは
可変長だと考えられます。
回数指定の反復で利用する、ワード「 i j k 」の周辺がどう
なっているのかを、見てみました。
ワード「irq-uart」、「irq-i2c」、「irq-adc」は、辞書の
中でも隣り合っているとわかります。
アドレスが、$0003A50、$00003A30、$00003A10となって
いるため、32バイトごとなので、アドレスフィールドは
可変長だと考えられます。
回数指定の反復で利用する、ワード「 i j k 」の周辺がどう
なっているのかを、見てみました。
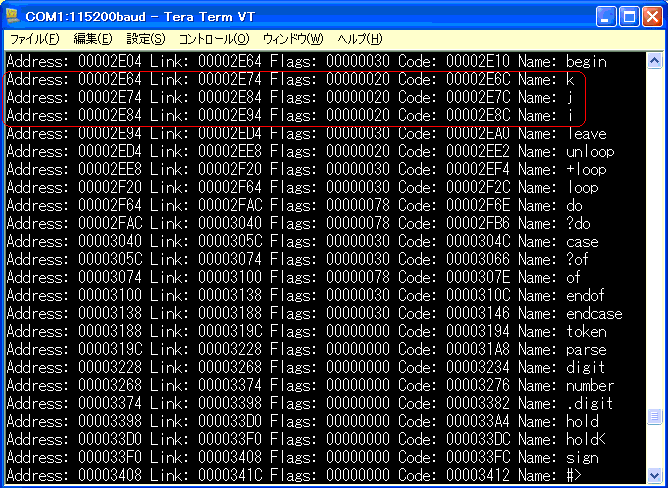 サイズが16バイトとなって、アドレスフィールドは
可変長で扱っているとみてよいでしょう。
変数を定義して初期値を設定したときに、どうなるのか
を見てみます。
サイズが16バイトとなって、アドレスフィールドは
可変長で扱っているとみてよいでしょう。
変数を定義して初期値を設定したときに、どうなるのか
を見てみます。
 リンクは、「-- Mecrisp-Stellaris Core ---」からで
文字列が含まれているアドレスが、エントリーアドレス
になってます。また、変数VAは、RAMの中にある辞書の
領域に格納されています。
それならば、変数VAのエントリーアドレスの中には
何が含まれているのかを見ます。
リンクは、「-- Mecrisp-Stellaris Core ---」からで
文字列が含まれているアドレスが、エントリーアドレス
になってます。また、変数VAは、RAMの中にある辞書の
領域に格納されています。
それならば、変数VAのエントリーアドレスの中には
何が含まれているのかを見ます。
 リンクアドレスが含まれているようです。
エントリーアドレスから、4バイトごとにどんな値が
格納されているのかを見てみます。
リンクアドレスが含まれているようです。
エントリーアドレスから、4バイトごとにどんな値が
格納されているのかを見てみます。
 リンクアドレスの次からを、リトルエンディアンで
並べてみると、以下。
40 00 02 56 41 00 04 3F
最初の 40 00 は、00 40 と並べるとFlagsと同じ。
56 41 は、ASCIIコードでは、V、Aになっています。
2バイトの前は、02でワード名の長さに相当。
56 41 は、英文字では'V'、'A'となっています。
文字列の最後にはデリミタをおいておけばよいので
41 の後の 00 がデリミタに相当します。
リンクアドレス、フラグ、ワード名、コードという
並びが採用されているよう。
リンクアドレスを持っているので、該当ワードの
前にあるワードが何かをたぐるのは、難しくない
とわかります。
実際に変数で定義された内容を含んでいるアドレスを
取得するには、次の処理で充分でした。
リンクアドレスの次からを、リトルエンディアンで
並べてみると、以下。
40 00 02 56 41 00 04 3F
最初の 40 00 は、00 40 と並べるとFlagsと同じ。
56 41 は、ASCIIコードでは、V、Aになっています。
2バイトの前は、02でワード名の長さに相当。
56 41 は、英文字では'V'、'A'となっています。
文字列の最後にはデリミタをおいておけばよいので
41 の後の 00 がデリミタに相当します。
リンクアドレス、フラグ、ワード名、コードという
並びが採用されているよう。
リンクアドレスを持っているので、該当ワードの
前にあるワードが何かをたぐるのは、難しくない
とわかります。
実際に変数で定義された内容を含んでいるアドレスを
取得するには、次の処理で充分でした。
 ここまでの実験から、このForthインタプリタでは
辞書の管理テーブルの1ブロックは、以下のように
なっていると考えられます。
ここまでの実験から、このForthインタプリタでは
辞書の管理テーブルの1ブロックは、以下のように
なっていると考えられます。
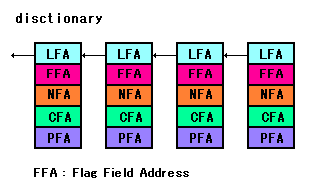 NFA、CFAが可変長で、他は固定長で管理していると
見て間違いないでしょう。
サンプルのワード定義から、ARMプロセッサのレジスタが
どう利用されているのかがわかります。
READMEの中には、アセンブリ言語レベルで内蔵レジスタ
をどう利用しているのかが書かれています。
ARMの汎用レジスタは、次の役割を与えています。
NFA、CFAが可変長で、他は固定長で管理していると
見て間違いないでしょう。
サンプルのワード定義から、ARMプロセッサのレジスタが
どう利用されているのかがわかります。
READMEの中には、アセンブリ言語レベルで内蔵レジスタ
をどう利用しているのかが書かれています。
ARMの汎用レジスタは、次の役割を与えています。
- r0 general purpose
- r1 general purpose
- r2 general purpose
- r3 general purpose
- r4 loop counter
- r5 loop limited value
- r6 TOP-STACK
- r7 Parameter Stack Pointer
目次 前 次