配列処理
Forthの言語仕様には、配列が存在しません。 配列は、メモリ上に用意するブロックで代用します。 メモリ上のブロックを扱うワードは、以下。
- [char] * Compiles code of following char ( -- char ) when executed
- char * ( -- char ) gives code of following char
- buffer: name ( u -- ) Creates a buffer in RAM with u bytes length
- move ( c-addr1 c-addr2 u -- ) Moves u Bytes in Memory
- fill ( c-addr u c ) Fill u Bytes of Memory with value c
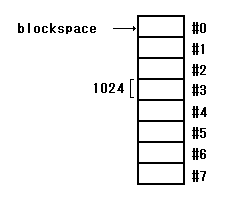 計算でスタックにどんな値を入れるのかを見ていきます。
blockspaceは、ブロックの先頭アドレスを示すので、目的の
データを含んでいるアドレスを計算するワードが、以下。
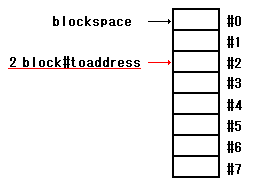
: block#toaddress ( n -- addr ) blocksize * blockspace + ;
このワードには、パラメータが必要で、ブロック番号を指定。
パラメータとして2を入れると、ワード「block#toaddress」が
求めるのは、2ブロック目の先頭アドレスがスタックに入ります。
計算でスタックにどんな値を入れるのかを見ていきます。
blockspaceは、ブロックの先頭アドレスを示すので、目的の
データを含んでいるアドレスを計算するワードが、以下。
: block#toaddress ( n -- addr ) blocksize * blockspace + ;
このワードには、パラメータが必要で、ブロック番号を指定。
パラメータとして2を入れると、ワード「block#toaddress」が
求めるのは、2ブロック目の先頭アドレスがスタックに入ります。
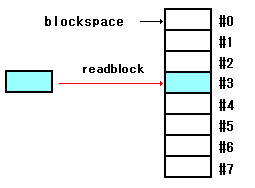
 ブロックを指定し、その内部をリードするワードを見てみます。
: readblock ( block# addr -- ) ." Read block " over u. ." into " dup hex. cr swap block#toaddress swap blocksize move ;
このワードには、パラメータが必要でブロックの先頭アドレスを指定。
ワード「over」を利用して、ソースとなるブロックの先頭アドレスを
スタックトップにした後ディストネーションの先頭アドレスと共に
表示しています。
ブロックサイズ分のデータを、ワード「move」を利用してコピー。
図で見ると、以下。
ブロックを指定し、その内部をリードするワードを見てみます。
: readblock ( block# addr -- ) ." Read block " over u. ." into " dup hex. cr swap block#toaddress swap blocksize move ;
このワードには、パラメータが必要でブロックの先頭アドレスを指定。
ワード「over」を利用して、ソースとなるブロックの先頭アドレスを
スタックトップにした後ディストネーションの先頭アドレスと共に
表示しています。
ブロックサイズ分のデータを、ワード「move」を利用してコピー。
図で見ると、以下。
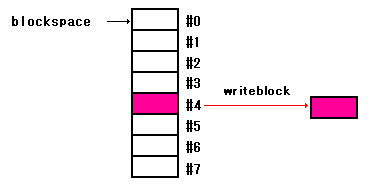
 ブロックを指定し、その内部にデータを格納するワードを見ていきます。
: writeblock ( block# addr -- ) ." Write " dup hex. ." into block " over u. cr swap block#toaddress blocksize move ;
ワード「dup」を利用して、ソースとなるブロックの
先頭アドレスを表示後、ディストネーションの先頭
アドレスを利用して、ワード「move」を利用してコピー。
ワード「readblock」との違いは、ソースとなるブロックの
アドレスが、独自に確保したブロックを利用していると
いうこと。
図で見ると、以下。
ブロックを指定し、その内部にデータを格納するワードを見ていきます。
: writeblock ( block# addr -- ) ." Write " dup hex. ." into block " over u. cr swap block#toaddress blocksize move ;
ワード「dup」を利用して、ソースとなるブロックの
先頭アドレスを表示後、ディストネーションの先頭
アドレスを利用して、ワード「move」を利用してコピー。
ワード「readblock」との違いは、ソースとなるブロックの
アドレスが、独自に確保したブロックを利用していると
いうこと。
図で見ると、以下。
 32ビットのプロセッサでは、1ワードのデータは32ビットで
扱うほうが、わかりやすいですが、メモリアドレスはバイト
で割り付けてあるので、ブロック内のデータの出し入れは
ワード(32ビット)単位になります。
ブロックにワード値を格納するたびに、バイトでふってある
アドレスに4を加算するのは面倒なので、ワード「cell+」が
用意されています。
動作を確認してみると、以下。
32ビットのプロセッサでは、1ワードのデータは32ビットで
扱うほうが、わかりやすいですが、メモリアドレスはバイト
で割り付けてあるので、ブロック内のデータの出し入れは
ワード(32ビット)単位になります。
ブロックにワード値を格納するたびに、バイトでふってある
アドレスに4を加算するのは面倒なので、ワード「cell+」が
用意されています。
動作を確認してみると、以下。
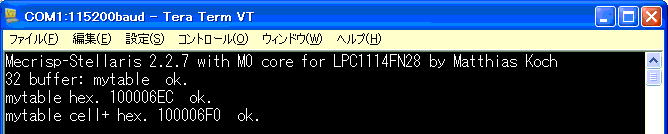 ワードは、細胞を意味するセル(cell)で扱われています。
1セル分のアドレスを増やすことが、4を加算することに
相当しています。
セルという概念で、ブロックに入っているデータを表示する
ことができます。そのためのワードを使って確認しましょう。
ブロックの先頭と次のセルの内容を表示。
ワードは、細胞を意味するセル(cell)で扱われています。
1セル分のアドレスを増やすことが、4を加算することに
相当しています。
セルという概念で、ブロックに入っているデータを表示する
ことができます。そのためのワードを使って確認しましょう。
ブロックの先頭と次のセルの内容を表示。
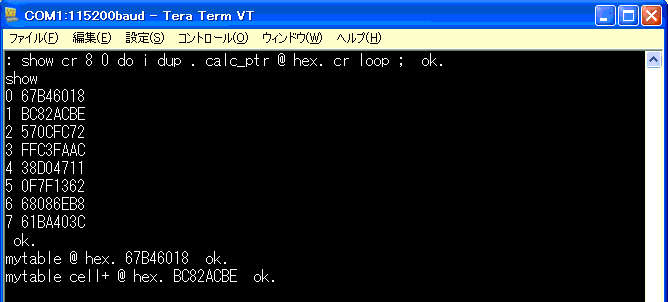 上から2行目、3行目で表示された内容が、ブロックの中の
4バイトデータを表示していくワードで公開された値と一致
しています。
ワード「@」は、スタックに値を格納する機能をもっていますが
値のサイズは、32ビット=1ワード=4バイト=1セルである
と判断してよいでしょう。
ワード「@」は、次のようにメモリ上のデータを出し入れする
ことになります。
上から2行目、3行目で表示された内容が、ブロックの中の
4バイトデータを表示していくワードで公開された値と一致
しています。
ワード「@」は、スタックに値を格納する機能をもっていますが
値のサイズは、32ビット=1ワード=4バイト=1セルである
と判断してよいでしょう。
ワード「@」は、次のようにメモリ上のデータを出し入れする
ことになります。
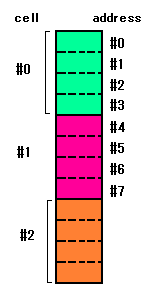 これまでの内容は、わかりにくかったので、ワード
「buffer: 」を利用して簡単なテストをしてみます。
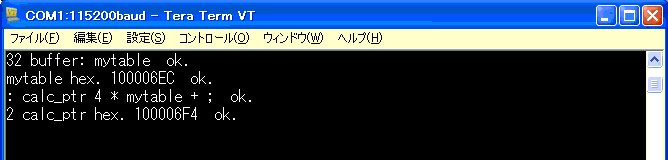
32バイト=8ワードのデータ領域を確保し、その
先頭アドレスを表示。
これまでの内容は、わかりにくかったので、ワード
「buffer: 」を利用して簡単なテストをしてみます。
32バイト=8ワードのデータ領域を確保し、その
先頭アドレスを表示。
 ブロックの先頭アドレスは、$100006EC。
この領域は、RAMへと割当てられてます。
LPC1114は、ARMのCortex-M0ベースなので、バイトごとに
アドレスを与えていても、32ビット=4バイトを一度に
扱います。
32ビット=4バイト=1ワードで扱っていることを
確認するために、ワードを定義しておきます。
ブロックの先頭アドレスは、$100006EC。
この領域は、RAMへと割当てられてます。
LPC1114は、ARMのCortex-M0ベースなので、バイトごとに
アドレスを与えていても、32ビット=4バイトを一度に
扱います。
32ビット=4バイト=1ワードで扱っていることを
確認するために、ワードを定義しておきます。
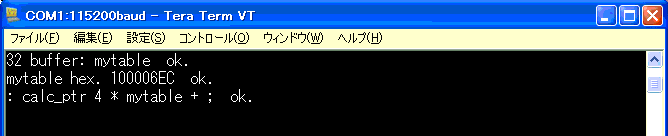 与えられた数だけ、ワード数だけアドレスが増える
ようにしてみました。動作を確認。
与えられた数だけ、ワード数だけアドレスが増える
ようにしてみました。動作を確認。
 確保したブロックの内容を表示できるようにすれば
ブロックの指定位置にデータを出し入れしたときに
値が変化しているのを確認しやすくなります。
確保したワード数だけループを回し、1ワードごとに
取出し、16進数書式で表示させればよいと考えました。
ワードの中でdo ... loopを利用します。
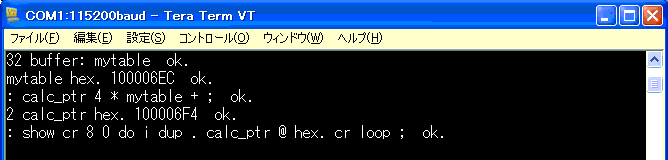
: show cr 8 0 do i dup . calc_ptr @ hex. cr loop ;
このワードを入力。
確保したブロックの内容を表示できるようにすれば
ブロックの指定位置にデータを出し入れしたときに
値が変化しているのを確認しやすくなります。
確保したワード数だけループを回し、1ワードごとに
取出し、16進数書式で表示させればよいと考えました。
ワードの中でdo ... loopを利用します。
: show cr 8 0 do i dup . calc_ptr @ hex. cr loop ;
このワードを入力。
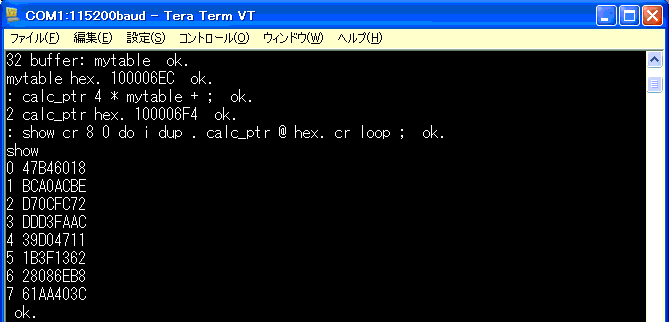
 定義したワードで、ブロックの内容を表示すると、以下。
定義したワードで、ブロックの内容を表示すると、以下。
 ブロックの1ワード目に値格納後、再度内容を表示してみます。
ブロックの1ワード目に値格納後、再度内容を表示してみます。
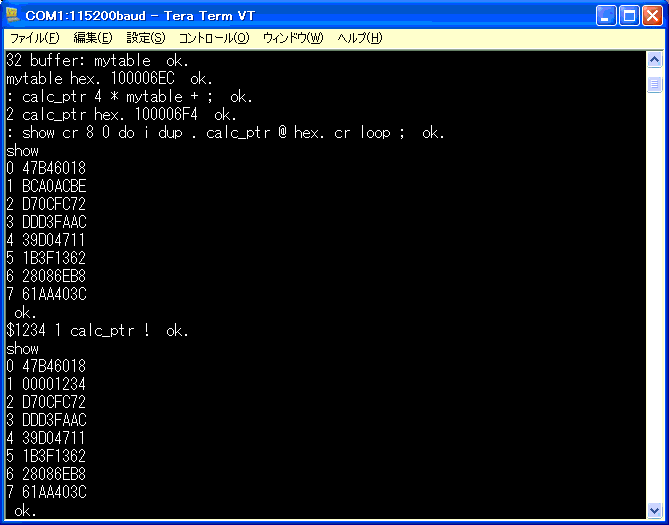 内容が変化したことがわかります。
指定バイト分が確保されているのかは、新たに定義した
ワードが、どのアドレスから格納されているのかを見て
みれば、判断できます。
ワード「words」で、辞書内にあるアドレスを確認。
内容が変化したことがわかります。
指定バイト分が確保されているのかは、新たに定義した
ワードが、どのアドレスから格納されているのかを見て
みれば、判断できます。
ワード「words」で、辞書内にあるアドレスを確認。
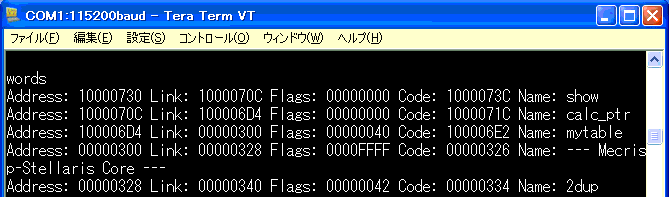 ブロック定義でmytableを確保したときには、アドレスが$100006EC。
新たに定義したワード「calc_ptr」は、$1000070C。
32=$20となるので、mytableのアドレスに$20を加えてみます。
$100006EC+$20=$1000070Cより、間違いなく32バイト分の差。
ブロックが確保できているので、ワード「fill」を使って指定する
データでブロック内を埋めてみます。
ブロック定義でmytableを確保したときには、アドレスが$100006EC。
新たに定義したワード「calc_ptr」は、$1000070C。
32=$20となるので、mytableのアドレスに$20を加えてみます。
$100006EC+$20=$1000070Cより、間違いなく32バイト分の差。
ブロックが確保できているので、ワード「fill」を使って指定する
データでブロック内を埋めてみます。
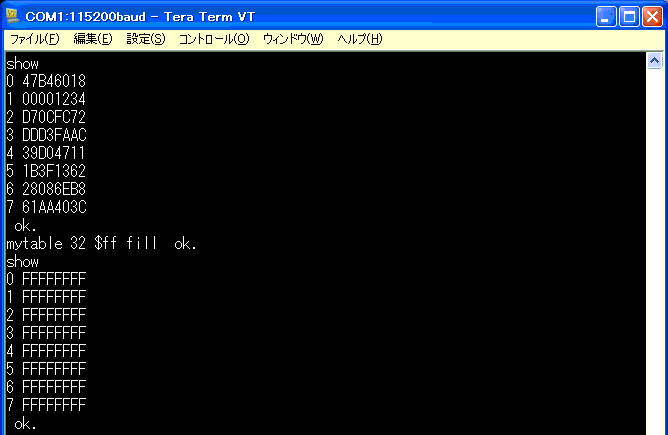 問題なく、指定データでブロック内を満たすことができました。
偶然でないことを、別のデータを指定して確認。
問題なく、指定データでブロック内を満たすことができました。
偶然でないことを、別のデータを指定して確認。
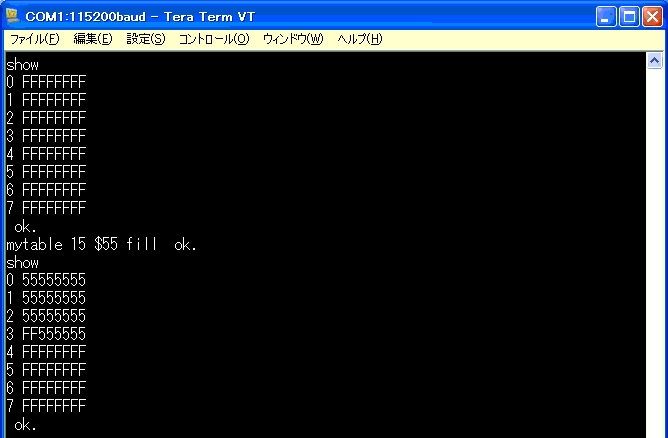 間違いなく、ワード「fill」で指定データで埋められています。
確保したブロックを、配列として利用するには、ワードだけで
なく、1バイトか2バイトで扱えないと、使い勝手がよくない
でしょう。
バイトで扱う場合は、該当する位置が、どのワード位置に含まれて
いるのかを計算してから、データを取得するか、設定すれば充分。
商と剰余の計算をすれば、バイト位置とワード位置の
相互変換が可能になります。
1バイトごとのデータ格納は、fillを使えば簡単。
バッファに1バイトのデータをfillすると考えます。
Forthのコードでは、以下のようにすれば充分。
: mysta mytable + swap 1 swap fill ;
ワードを入力して動作を確認してみます。
間違いなく、ワード「fill」で指定データで埋められています。
確保したブロックを、配列として利用するには、ワードだけで
なく、1バイトか2バイトで扱えないと、使い勝手がよくない
でしょう。
バイトで扱う場合は、該当する位置が、どのワード位置に含まれて
いるのかを計算してから、データを取得するか、設定すれば充分。
商と剰余の計算をすれば、バイト位置とワード位置の
相互変換が可能になります。
1バイトごとのデータ格納は、fillを使えば簡単。
バッファに1バイトのデータをfillすると考えます。
Forthのコードでは、以下のようにすれば充分。
: mysta mytable + swap 1 swap fill ;
ワードを入力して動作を確認してみます。
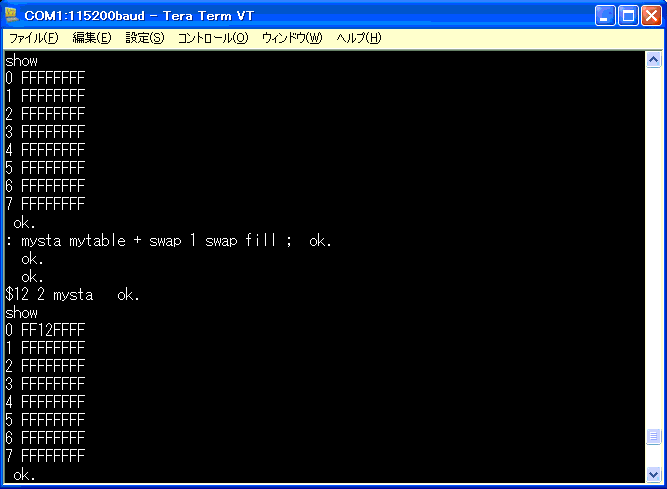 間違いなく、指定したバイト位置にデータが格納されました。
指定した位置のバイトデータを取り出すためには、ワード「@」を
使って、ワード(4バイト)をスタックに入れて、シフトして取得
すればよいはず。
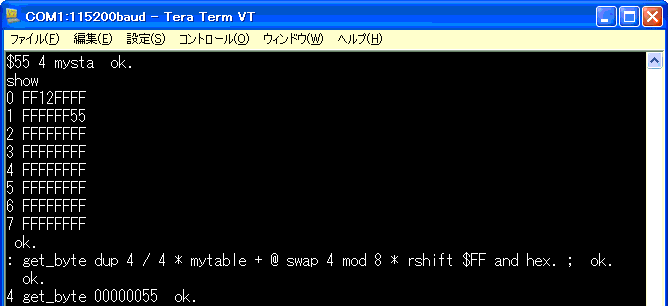
: get_byte dup 4 / 4 * mytable + @ swap 4 mod 8 * rshift $FF and hex. ;
バイト位置を2回利用しています。
4バイトごとにワードの境界があるので、4で割った商と
余りを使って、商からワード位置を計算し、そのワードの
どこに相当するのかを余りで算出。
4バイト目の値を変更後、取り出してみます。
間違いなく、指定したバイト位置にデータが格納されました。
指定した位置のバイトデータを取り出すためには、ワード「@」を
使って、ワード(4バイト)をスタックに入れて、シフトして取得
すればよいはず。
: get_byte dup 4 / 4 * mytable + @ swap 4 mod 8 * rshift $FF and hex. ;
バイト位置を2回利用しています。
4バイトごとにワードの境界があるので、4で割った商と
余りを使って、商からワード位置を計算し、そのワードの
どこに相当するのかを余りで算出。
4バイト目の値を変更後、取り出してみます。
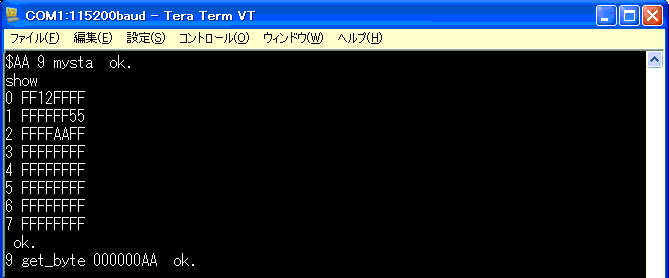
 もうひとつデータを変更して試してみます。
もうひとつデータを変更して試してみます。
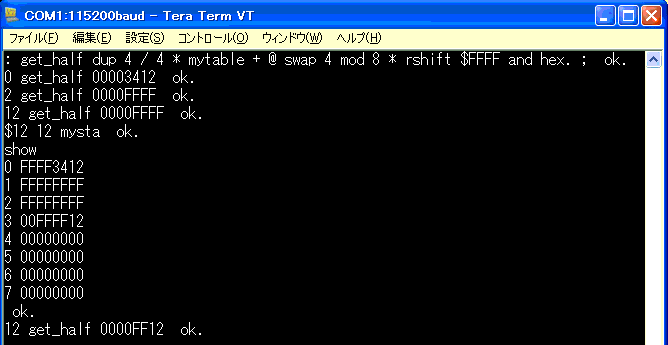
 バイトでの入出力ができたので、16ビットでの表示を
担当するワードを定義します。
: get_half dup 4 / 4 * mytable + @ swap 4 mod 8 * rshift $FFFF and hex. ;
試してみましょう。
バイトでの入出力ができたので、16ビットでの表示を
担当するワードを定義します。
: get_half dup 4 / 4 * mytable + @ swap 4 mod 8 * rshift $FFFF and hex. ;
試してみましょう。
 どうやら、これでよいようです。
16ビットでの表示ができたので、16ビットデータの格納を考えます。
16ビットの設定はバイトの設定を2回実行で対応すればよいでしょう。
スタックをジャグリングする方法で、ワード「mysta」を
2回利用できるようにしてみます。
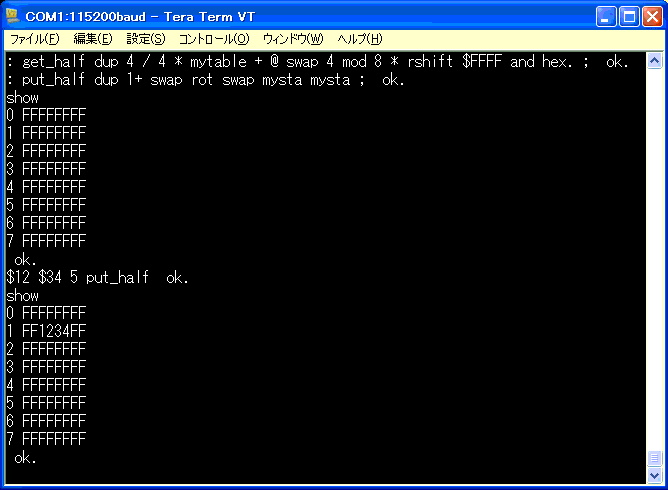
: put_half dup 1+ swap rot swap mysta mysta ;
ワード「mysta」は、1バイトのデータを格納するので
次のようにパラメータを渡すようにすればいけそうと
考えました。
$12 5 mysta $34 6 mysta
16ビットデータを上位、下位の順に指定して、下位の
1バイトを渡す仕様としました。
$12 $34 5 put_half
ワードを入力して、テスト。
どうやら、これでよいようです。
16ビットでの表示ができたので、16ビットデータの格納を考えます。
16ビットの設定はバイトの設定を2回実行で対応すればよいでしょう。
スタックをジャグリングする方法で、ワード「mysta」を
2回利用できるようにしてみます。
: put_half dup 1+ swap rot swap mysta mysta ;
ワード「mysta」は、1バイトのデータを格納するので
次のようにパラメータを渡すようにすればいけそうと
考えました。
$12 5 mysta $34 6 mysta
16ビットデータを上位、下位の順に指定して、下位の
1バイトを渡す仕様としました。
$12 $34 5 put_half
ワードを入力して、テスト。
 問題はないようです。
メモリエリアの一部に、バイトサイズでブロックを
確保して、バイト、ハーフワード、ワード単位での
データの出し入れができるようにしました。
これで配列の操作が可能になったと断言してよいでしょう。
ワードcreateを利用して、バイト単位の配列を確保する
ことが可能です。
allotを利用して、次のように8バイト分を確保し
値を格納してみます。さらに、表示ワードを定義
します。
create ntbl 8 allot
3 ntbl 0 + c! 2 ntbl 1 + c!
3 ntbl 2 + c! 3 ntbl 3 + c!
1 ntbl 4 + c! 3 ntbl 5 + c!
3 ntbl 6 + c! 3 ntbl 7 + c!
: shown cr 8 0 do i dup . ntbl + c@ . cr loop ;
フェッチとストアには、1バイト単位で扱える
ワードのc@、c!を使っています。
どうなるのかを、確認すると以下。
問題はないようです。
メモリエリアの一部に、バイトサイズでブロックを
確保して、バイト、ハーフワード、ワード単位での
データの出し入れができるようにしました。
これで配列の操作が可能になったと断言してよいでしょう。
ワードcreateを利用して、バイト単位の配列を確保する
ことが可能です。
allotを利用して、次のように8バイト分を確保し
値を格納してみます。さらに、表示ワードを定義
します。
create ntbl 8 allot
3 ntbl 0 + c! 2 ntbl 1 + c!
3 ntbl 2 + c! 3 ntbl 3 + c!
1 ntbl 4 + c! 3 ntbl 5 + c!
3 ntbl 6 + c! 3 ntbl 7 + c!
: shown cr 8 0 do i dup . ntbl + c@ . cr loop ;
フェッチとストアには、1バイト単位で扱える
ワードのc@、c!を使っています。
どうなるのかを、確認すると以下。
 Forthでは、Enterキーを叩くまでに入力したワードは
バッファに入っていくので、1行に複数の内容を書き
見やすくしてあります。
Forthでは、Enterキーを叩くまでに入力したワードは
バッファに入っていくので、1行に複数の内容を書き
見やすくしてあります。
目次 前 次